
Developing web apps with local LLM inference

Abdelrahman Hosny
on 21 May 2026
Tags: AI , Inference Snaps , Ubuntu
I’ve yet to meet a developer that enjoys working with metered AI APIs. The need to pay for every API call in development works in direct opposition to the ethos of rapid iteration, and it’s easy for the costs to get out of hand. That’s why Canonical has created a different approach to building AI-powered applications; one where the model lives inside your app, not behind a pay-per-token HTTP call. This post walks through the ideas behind Embedded AI – integrating local LLM inference directly into your app – and demonstrates those ideas in practice on the NVIDIA DGX Spark.
The problem with remote AI services
Today’s default architecture for AI-powered applications is a hub-and-spoke model: multiple applications each call out to a shared AI service (OpenAI, Anthropic, Google Gemini, etc.). That service is responsible for running inference, metering usage, enforcing rate limits, and billing you by the token.
This model solves one real problem: you do not have to manage GPU infrastructure yourself. But it introduces several others:
- Cost unpredictability. Every call has a marginal cost. In development, where you iterate fast and make many exploratory requests, those costs compound quickly and often surprise teams mid-sprint.
- Network latency. A round-trip to a remote API adds tens to hundreds of milliseconds per request. For applications that chain multiple model calls (agents, RAG pipelines, multi-step reasoning), the latency accumulates and degrades user experience.
- Data privacy. Sending sensitive data to a third-party service requires trust in that service’s data policies, creates compliance complexity, and may simply be prohibited in regulated industries.
- Dev-to-production friction. Development environments stub the API or use different credentials than production. Configuration drift, mock/real mismatches, and environment-specific behavior all stem from the fact that the “AI” in development is not the same thing as the “AI” in production.
- Operational complexity. Rotating API keys, managing quotas across teams, handling upstream outages, and understanding why a model behaves differently today versus last week are all problems that come bundled with remote AI services.
From AI services to local LLM inference
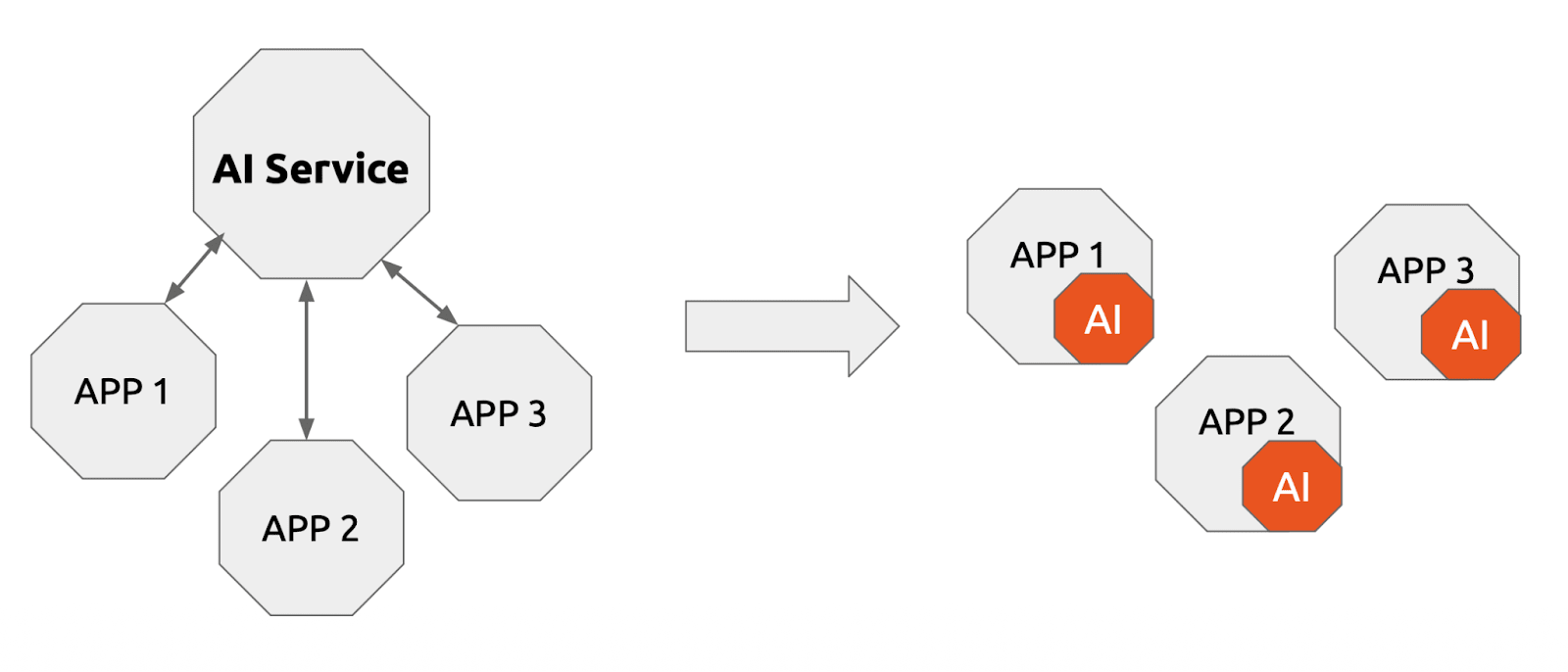
The idea behind Embedded AI is straightforward: treat the model and its inference runtime the way you already treat a software package as a local dependency of your application, not as a remote third-party service.
Instead of three apps all calling a shared external endpoint:
- APP 1 ──┐
- APP 2 ──┤──► AI Service (remote, metered, shared)
- APP 3 ──┘
Each app packages and runs its own inference engine:
- APP 1 + AI (local, free at runtime, isolated)
- APP 2 + AI (local, free at runtime, isolated)
- APP 3 + AI (local, free at runtime, isolated)
This idea mirrors how organizations moved from server-side database instances to local SQLite, or from shared Redis clusters to in-process caches for appropriate workloads. The question is whether the hardware and the packaging tooling have caught up enough to make it practical.
In 2026, the answer is increasingly yes.
Inference snaps: installing AI like a package
The friction in running local LLM inference has historically been setup complexity: installing NVIDIA CUDA drivers, choosing the right quantization for your GPU’s VRAM, configuring the inference server, managing updates. Canonical’s inference snaps solve this.
An inference snap packages together:
- The model weights in a format optimized for local hardware
- The inference runtime (llama.cpp, vLLM, or others, selected automatically)
- Hardware-specific optimizations (quantization level, batching strategy, inference engine selection)
- A standard OpenAI-compatible HTTP API exposed locally
- Dependency management and automatic updates via the Snap store
The snap’s engine manager detects your hardware at install time and selects the engine that makes best use of your CPU, GPU, or NPU. You do not choose quantization manually. You do not install CUDA toolkit by hand. You run one command:
sudo snap install gemma3With that, you have a locally running Gemma 3 inference server exposing an OpenAI-compatible endpoint, hardware-optimized, with automatic updates. The model is immediately usable from any application that knows how to make an HTTP call.
Snaps expose a content interface mechanism that lets other snaps (your application) read the endpoint URL from a shared status.json file:
sudo snap connect demo-app:inference-snap-status gemma3:status
After this connection, your application can read exactly where the inference endpoint is listening without any configuration file or environment variable management. The snap system handles the plumbing.
The reference implementations
The embedded-ai repository contains two concrete examples, both built as snaps themselves, so they integrate cleanly with the inference snap ecosystem.
App 1: simple chat
The first example (_01_simple_chat) is deliberately minimal. It demonstrates the core pattern: a snap-packaged Python application that reads the inference endpoint from the Gemma 3 snap’s status interface and streams a chat completion to stdout.
Building and running:
# Build the snap
cd _01_simple_chat && snapcraft pack # or: make build
# Install it
sudo snap install demo-app_*.snap --dangerous --devmode
# Connect it to the inference snap
sudo snap connect demo-app:inference-snap-status gemma3:status
# Run it
demo-appThe app streams a single chat completion using the model exposed by the inference snap. Because the inference snap exposes an OpenAI-compatible API, the Python code looks identical to code that calls api.openai.com; except the base URL points to localhost and there is no API key. The model runs on your machine. The cost of that call is electricity.
This pattern has an important architectural implication: your application code is decoupled from the specific model. Swap gemma3 for a different inference snap (say, qwen-vl or nemotron-3-nano), re-run the snap connect, and your app works against the new model with zero code changes.
App 2: PDF summarizer
The second example (_02_pdf_summarizer) shows a more realistic use case: processing a document and generating a summary using the local model.
Building and running:
# Build the snap
cd _02_pdf_summarizer && snapcraft pack # or: make build
# Install it
sudo snap install pdf-summarizer_*.snap --dangerous --devmode
# Connect to the inference snap
sudo snap connect pdf-summarizer:inference-snap-status gemma3:status
# Summarize a PDF
pdf-summarizer /path/to/document.pdfThe app reads the PDF from disk, sends its content to the local LLM inference endpoint, and streams a concise summary to stdout. Notice what is not happening here: the PDF contents are not leaving your machine. They are not being sent to a third-party API. There is no data processing agreement to worry about, no risk of training data contamination, no latency from a WAN round-trip. The model reads your document locally and gives you an answer.
For enterprise use cases involving legal documents, medical records, financial reports, or any other sensitive material, this distinction is often the deciding factor in whether AI-powered features can be built at all.
Why package your app as a snap too?
You might wonder: why package the demo apps themselves as snaps? You could just run a Python script that calls localhost:PORT.
The answer is about distribution and dependency management. When your application is a snap:
- Dependencies are bundled. Your Python version, pip packages, and any native libraries are frozen in the snap. No
virtualenvsetup, nopip install -r requirements.txton the target machine. - The content interface works cleanly. The snap system’s connection mechanism lets your app and the inference snap share a secure, well-defined channel for discovering the endpoint URL. This is cleaner than environment variables or config files and works correctly across snap updates.
- Your app updates like software. Snap updates are atomic and rollback-safe. If an update breaks something, you revert with one command.
- You ship once, run anywhere Ubuntu runs. The same snap package that runs on your DGX Spark runs on an Ubuntu server in a data centre, on edge devices with a supported GPU, or on any Ubuntu Certified hardware.
This is the realization of the dev-to-production parity promise: you develop, test, and ship the same artifact.
When does local LLM inference make sense?
Local AI is not the right answer for every situation. It makes the most sense when:
Privacy is a hard requirement. Legal, medical, financial, or government workloads where data cannot leave the premises are natural fits.
Latency matters. Applications that call the model in a tight loop (agents, real-time assistants, streaming pipelines) benefit enormously from eliminating network round-trips.
Costs would otherwise scale with usage. Internal tools used heavily by a team, e.g. code review assistants, document summarizers, knowledge base Q&A, accumulate token costs fast. A one-time hardware investment can amortize quickly against ongoing API bills.
Dev-to-production parity is important. Teams that are tired of “works against the API in dev, behaves differently in prod” issues benefit from having the exact same model and runtime in every environment.
Offline or air-gapped environments. Manufacturing floors, research labs, field deployments, and any environment without reliable internet connectivity need local inference by necessity.
It is less suitable for workloads that genuinely need frontier model scale (where a 70B local model is not competitive with a 200B+ remote one), or for sporadic, low-volume AI use where the hardware investment does not justify itself.
Getting started
Everything described in this post is open source and documented:
Inference snaps documentation and tutorials
The fastest path to running your first locally-inferred completion:
# 1. Install the model snap
sudo snap install gemma3
# 2. Clone the reference repo
git clone https://github.com/abdelrahmanhosny/embedded-ai.git
cd embedded-ai/_01_simple_chat
# 3. Build and install the demo app snap
snapcraft pack # or: make build
sudo snap install demo-app_*.snap --dangerous --devmode
# 4. Connect the app to the inference snap
sudo snap connect demo-app:inference-snap-status gemma3:status
# 5. Run it
demo-appThat is all it takes to go from zero to a locally-running, hardware-optimized, OpenAI-compatible LLM serving your application; no API key, no monthly bill, no data leaving your machine.
The code examples in this post reference the embedded-ai repository at commit main as of May 2026. The Inference Snaps project is maintained by Canonical under an open source license.
Talk to us today
Interested in running Ubuntu in your organisation?
Newsletter signup
Related posts
Finding the blind spot: How Canonical hunts logic flaws with AI
AI is accelerating and improving how security engineers find and fix vulnerabilities. A new tool developed and used at Canonical, called Redhound, has already...
Three weeks to go: A sneak peek of the Ubuntu Summit 26.04 experience
The countdown to the Ubuntu Summit is officially on! We are just three weeks away from Ubuntu Summit 26.04, and the orange energy levels in our community...
From Jammy to Resolute: how Ubuntu’s toolchains have evolved
We cover new toolchain versions, devpacks and workflows that improve the developer experience. The evolution of Ubuntu’s toolchains story goes beyond just...